
Introduction
P5 version 7 has a new container storage format, for backup and archive to cloud storage. This new format makes it possible to reduce the transmission overhead between source and destination for more efficient use of cloud storage.
This new container storage format is necessary for two reasons: Firstly it allows more efficient writing to cloud object storage, and secondly more practical deletion of data when it’s no longer required because it falls outside of the backup retention period.
Interacting with cloud object stores
Let us explore what this means in more detail. Why is writing to cloud object storage different to writing to a local hard disk? To understand this, we need to understand how data is written to cloud storage in more detail.
All cloud storage vendors have the concept of an ‘object’, which is a unit of storage within their cloud service. Objects can or almost any size, from very small to huge and might contain any kind of data, from PDFs, images, videos or databases. Anything can be stored within an object. Let us consider two ways we might store a folder containing a variety of files being backed up into the object storage.
Option 1: Upload the folder and its files individually. Each file = 1 object.
Option 2: Compress the folder and all its files and upload the zip as a single object.
Each option has advantages and disadvantages.
Option 1 is simple to implement and transparent from the users perspective. Software required to do this doesn’t have to be very sophisticated.
Option 2 is more complicated, since it introduces the extra compressions step, which takes computational effort, both on writing and when restoring/reading the data. Additional storage space may be required while the compression takes place.
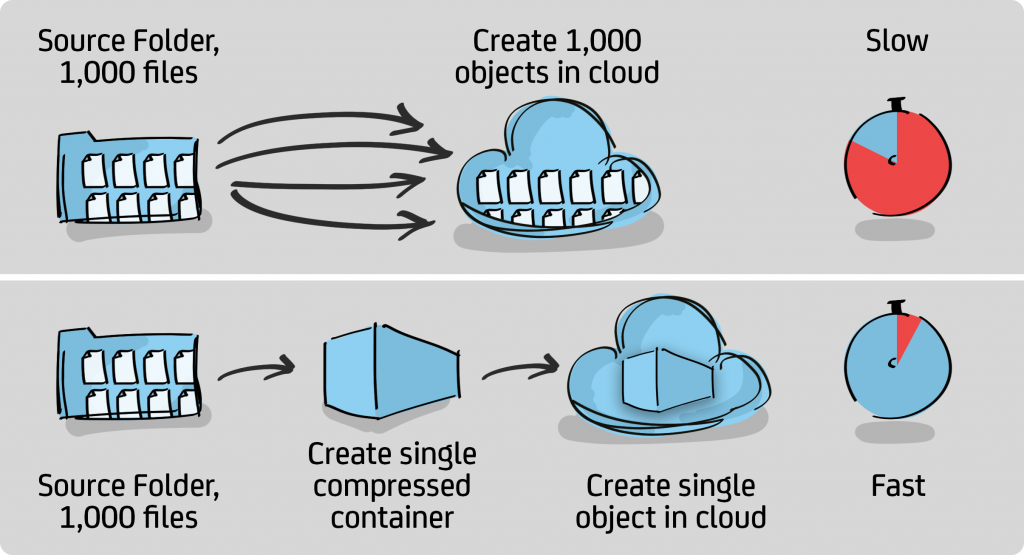
In return for the increased complexity, we get benefits. The total amount of data being stored in the cloud is reduced, perhaps significantly if the data being written is well suited to compression. Less data means lower costs, both for storage and upload/download costs.
The bigger advantage of option 2 is that, by not transmitting every file individually, we get the advantage that we don’t have to suffer the transmission overhead required for every object we send. Such an overhead exists for each object stored and can be significant. This is an immense advantage. If we have 1,000 files that fit within a single compressed object, then we are storing one object into the cloud, instead of 1,000. This makes it possible for backups to be possible that would not otherwise be practical.
We’re all aware that the speed at which we can transmit a file into the cloud is largely dependent upon the internet speed available (bandwidth) which can vary widely between sites, times of day and also between upload and download speeds on the same connection. But in addition to these speed limits, there’s an overhead for each operation that takes place against the cloud storage. For each operation a new connection is made, authentication takes place, storage bucket is checked, checksums are calculated. A whole series of http requests takes place, with network latency additionally impacting on performance. In many ways, we are at the mercy of the cloud vendors’ infrastructure here, with their systems optimised to maximise their profits, sometimes at the expense of the performance we experience. It’s difficult to verify stated performance claims against experienced reality. Whether the file is 1 kilobyte or hundred of gigabytes, the same overhead prevails.
So it’s clear that transferring lots of small files will not make best use of the connection to the cloud storage. In fact, it is very inefficient and should be avoided at all costs! A typical time needed to save a file is in the range 50-500 milliseconds. The backup/restore can be accelerated by uploading/downloading several files in parallel. It’s realistic to get 4-8 times more data transferred this way, but it requires more transactions = more latency/overhead.
Some numbers
Let’s look at a real-world example. A customer has around 300TB of data. Mostly large video files, but also around 850,000 small files of around 50KB. There is a 100Mbit internet connection with a real-world upload speed of around 10MB/second. For this customer, it takes around 0.5 seconds to upload one file.
Time requirement: 850,000 x 0.5 / 3600 = about 118 hours or 5 days
(Parallel uploads can reduce this time to one-fifth, or 24 hours/1 day)
Amount of data: 850,000 x 50kb = 42.5GB
Data size: 850,000 x 50kb = 42.5GB
So for only about 40GB of data it would take 24 hours/1 day to upload and the restore/download would take the same amount of time.
To be clear, in P5 container storage format, the same backup takes only 45 minutes. That’s faster by a factor of 32 – worlds of difference!
Interim conclusion: A backup in which each file is uploaded as a single object cannot be used in the professional professional sector, because it takes too long. Packing data before uploading is therefore mandatory.
P5’s new container storage format
As the term implies, files are grouped into ‘containers’. These containers have a minimum size (by default) of 256MB. Small files are thus grouped into these containers. Larger files claim a whole container for themselves. Additionally all containers are compressed.
Using this new method, latency during backup becomes a negligible factor. Companies using P5 without knowledge of data structures can use the Internet bandwidth to calculate the possible backup and restore capacity based on Internet bandwidth.
Existing P5 users will note that older versions also group data into ‘chunks, the disk driver for Virtual Tape Libraries (VTL) does this in version 6 already. These chunk files are part of a disk volume which is managed as a virtual tape library. In this way, a tape-like backup can be reproduced to hard disks, without changing the proven operations within P5. But this sounds complicated already, and it is!
Archiware felt that a cloud-based backup should be solved in a simpler way, without having to replicate the workings of tape in the method of setup and operation. Therefore it was felt necessary to develop a new storage format for P5 version 7.
Recycling of expired data in P5 version 6
Let us consider what happens when we perform a backup. We’re creating a copy of a set of files. Each file copy is retained for at least as long as the original exists on disk. We can specify how long we wish to retain each file after the original is deleted, e.g. 30 days. This way we have the option of restoring the original file, even if the original was deleted some time ago, perhaps accidentally.
Once we are outside of the required retention of a given file, it can be removed from the backup data in order to save capacity and thus cloud storage costs. This process of freeing up occupied storage space is, to some extent, a problem with the current ‘chunk’ implementation. With the existing system, we have a process called ‘recycling’, which takes place at the ‘volume’ level. The term ‘volume’ is also used to describe a whole LTO tape within P5. In the case of backup to cloud, a volume is fixed in size and contains many chunks. To recycle a volume that contains 50% of data that’s no longer needed (expired) we need to first re-save the 50% that is still available on disk (online) by backing it up again, so that the entire volume can be deleted.
In absolute numbers, this means that 1TB of a 2TB volume needs to be backed up again, to the cloud. By taking ‘progressive’ backups, P5 will perform this recycling of volumes and re-saving of data automatically. Another option is to schedule ‘Full’ backups that re-saves all data again, allowing older volumes to be recycled. However, repetition of full backups is best avoided when performing backups against cloud storage.
For many customers with sufficient bandwidth and an appropriately sized backup window this works satisfactorily. But, unfortunately, this solution does not scale, due to large amounts of data needing to be uploaded to the cloud from time to time.
Recycling of expired data in version 7
For these reasons, it became necessary to optimize the recycling mechanisms within P5, when writing to cloud storage. Hence the new container format in P5 version 7. In the new version, we are concerned with recycling ‘containers’ and not entire volumes. If all the data stored within a container is no longer needed (could be a single file) then the entire container can be deleted. If the container has some non-expired files inside, P5 only needs to re-save a relatively small amount of data to allow the container to be removed. This will be a small amount of data relative to the 256 MB chunk size.
This process of expiring containers and re-saving small amounts of data is distributed across the entire backup window and therefore doesn’t cause peaks where lots of additional data needs to be re-saved.
Fazit
The new P5 container storage format offers optimized storage handling for backup or archive to the cloud. It adapts perfectly to distributions of file sizes within customer data by packing small files together to best utilize latency while larger files are stored within their own containers. Performance can be further enhanced by utilizing several parallel uploads simultaneously.
This reduces the cloud storage costs the customer has to bear, with free space being released more quickly and the number of objects needing to be stored being greatly reduced. Fewer objects results in lower costs when replicating objects between locations.
Additionally, the new format has security advantages, with checksums generated at file-block and container level. Should the P5 server fail, the entire P5 configuration and backup indexes can be recovered directly from the cloud object store.