

by Marc M. Batschkus
An Archive is many things to many people. From reference to re-purposing, from monetization to service for clients, there are many perspectives on what an Archive can be and do. Since the perspectives vary so much, a closer look can reveal the potential hidden in this ancient term.

Archivum was the name the Romans gave buildings that stored scripture rolls which were no longer needed for daily affairs. Although we no longer use scripture rolls, the mechanism hasn´t changed much. The files we put in an Archive today are those that are no longer needed for daily production. This means the Archive is actually a data migration. Files are moved to the Archive and deleted from the source. This is already the main definition for Archive and distinction from a Backup which duplicates what is still being worked on. A synonym for Archive is data, file or media preservation, emphasizing the long-term character of the Archive.
There can be exceptions to this rule, but more on that later.
Why archive data in the first place? What Archive means: the archive process is a data migration from production storage to long-term Archive storage. As a result it frees up space on high performance production storage. If all completed projects move to the Archive it becomes the “Single Source of Truth” or the only place to look for any finalized files. This can save countless hours of searching files for re-use or returning customers.
Start by planning for the long-term
Whether the archive is meant for video footage, digitized film, photos, sounds, documents or any other files, planning is extremely important to get the best fit for the respective purpose and workflow. Investing time here, pays of later in many ways.
Since the Archive is a long-term project, you need to carefully consider who is involved now and in the future. A set of questions helps to discover all relevant actors and stakeholders.
All parties and perspectives need to be gathered and their input documented. The more perspectives can be gathered from people involved, the better the support for the Archive project will be. The usefulness improves also with multiple perspectives. Think ahead and speculate about future tasks, changes in the workflow and new people entering the company. What needs to be put in the Archive now in terms of metadata, what needs to be documented so that it will be useful for the future?
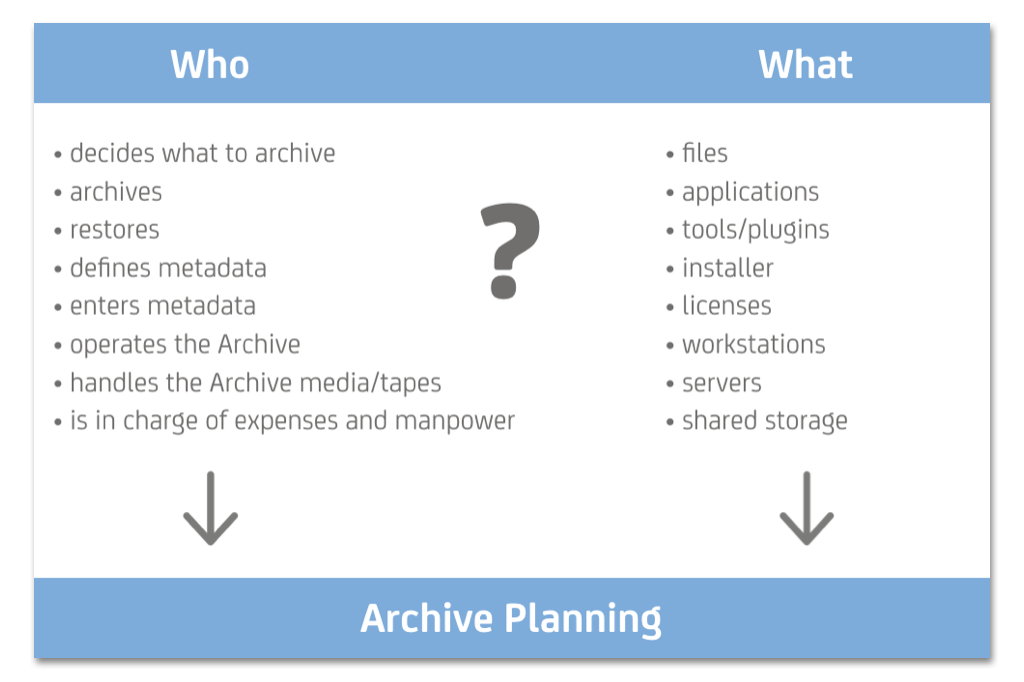
Use cases
The most efficient way to discover important factors for a system that is not yet in place is to write use cases. Use cases are stories where you describe in detail who is doing what with a system to fulfill what task.
Find all those involved in running and using the Archive later. Who are the stakeholders? What are the preconditions?
A use case could look like this:
A person (describe role or position) is signed a task where he needs (describe assets, files). He has the following information available (describe). He turns to the Archive to search for files that fit the assigned task. He searches for (describe). He browses the entries in the Archive catalog and decides which ones to restore (describe how). He/someone else triggers the restore process. Some time later the restored files are restored to (where) and used by (whom).
Try to come up with several of these scenarios and complete them with details. It makes sense to sit together with your colleagues to think about future scenarios and details. This will give you plenty of insight into what you need to install in terms of metadata and workflow to create an Archive that serves the company best.
Helpful hints how to write a use case can be found here:
http://www.wikihow.com/Write-a-Use-Case

Archive storage
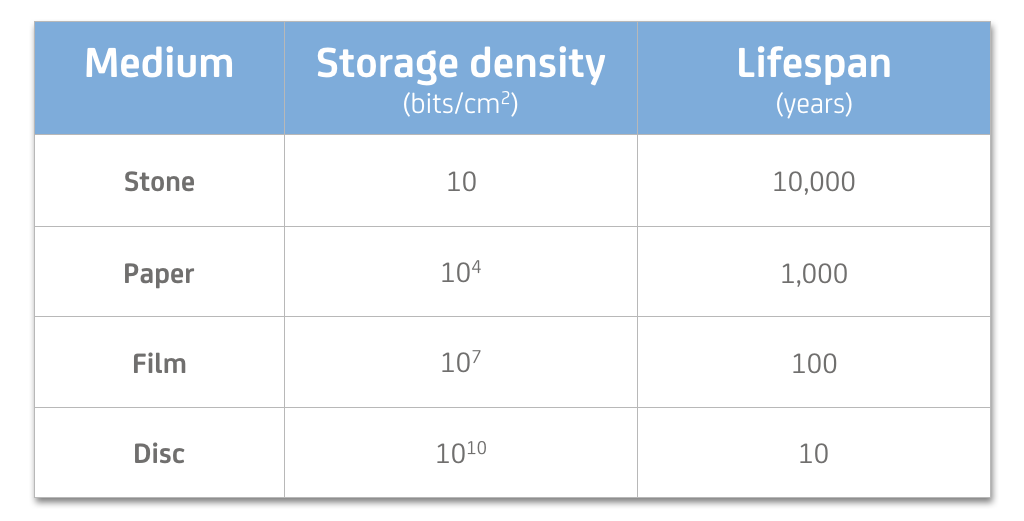
Looking at the history of storage media, there is an inverted relation of storage media density and their lifespan. While stone (engraving) retains information for very long, its information density is very low. Hard disk storage on the other end of the spectrum has an incredible storage density but a very short lifespan and depends on other technology to be available to read. LTO tape has a lifespan of several decades, but compared to historical dimensions this is still short. Therefore, migration is an integral part of any digital Archive. LTO makes this easy since each new generation is capable of reading media from two previous generations (e.g. LTO-7 can read LTO-5 tapes). There is a re-purchase guarantee by some vendors of 10 years that creates a great deal of flexibility for migrations. Right now and for the foreseeable future, LTO tape seems to be the only and most proven Archive medium. No other storage technology today can rival its density, durability, read/write performance and price per TB. Also, the sheer volume of the market and its global use in big industries like finance, insurance, broadcast, science, etc. make it very likely to continue in its role. It remains to be seen if cold disk storage or other technologies develop enough momentum to attract relevant market share.
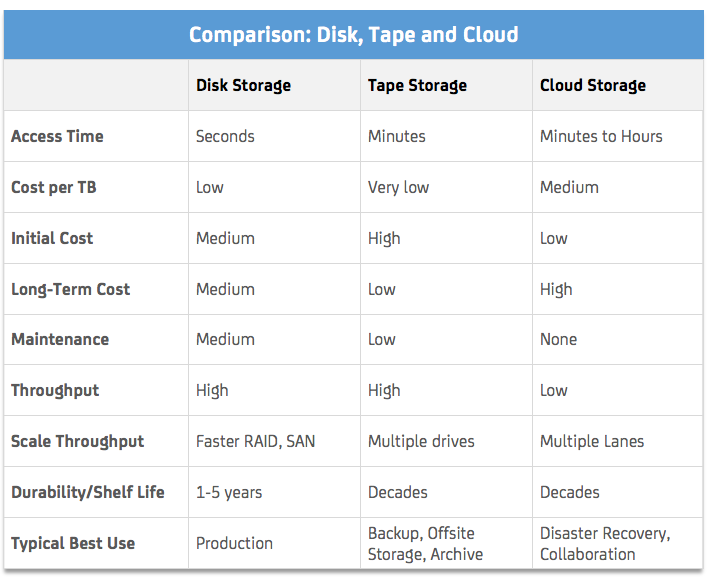
As of now, the main decision for Archive storage remains between disk, tape and cloud storage. Depending on the amount of data, the usage pattern, security requirements and available budget, each technology has its respective benefits.
Metadata – the key to unlock the Archive
Metadata plays a crucial part since it is the key to the Archive. Years after files have been archived, nobody might remember any specifics such as file names.
So the only option is to search for the right keyword, description or parameter – or in other words: metadata. There are two kinds of metadata: descriptive and technical.
Descriptive metadata needs human input like who is visible in a scene, what product was filmed, what location was used etc.
Technical metadata can be the type of camera used, lens, resolution, codec etc. Automatic generation of metadata (in cameras or during ingest) is advancing fast, one example being the shot detection in FCP X. These types of automatically created metadata can be very helpful. Additional descriptive metadata is – in most cases – a must. AI services that recognize content and speech are growing fast and will add tremendously to the metadata field in the future.
In some cases, a third kind of metadata might be needed, such as administrative metadata describing rights for use and distribution, for example.
A metadata schema is the set of technical and descriptive metadata that is used for an Archive and enables fast retrieval of files. It needs careful consideration and planning for the future. The combination of terms might be unique because it has to serve the requirements of your workflow or organization. The use cases that you put together should point towards the necessary items that need to be included in your specific schema.
One important aspect of metadata is consistency. Consistent tagging of archived files adds tremendous value to the Archive. Ideally, anyone involved in searching assets later should be able to easily find and restore them. P5 Archive offers extensible metadata fields and dropdown menus to put such a metadata schema to work.
— End of part 1, read part 2 —
