
From time to time, we are asked if P5 will copy/replicate individual files from a filesystem to a cloud object store, where one file is stored as one object. This seems a natural way to work, since cloud storage works with ‘files’, which we’re familiar with. Since, by design, P5 does not support using cloud storage in this way, this article will explain the thinking behind this implementation choice, with reference to cloud object stores and filesystems and the differences therein.

The purpose of the P5 Backup and Archive products is to store a copy of your files/folders either for DR or long term archive. P5 Synchronize replicates files/folders from one filesystem to another. Since a cloud object store appears to have much in common with a filesystem that you might maintain on-premise, why does it therefore not make sense to make a simple one-to-one copy of the on-site data to the cloud object store?
An Object Store is not a Filesystem
To understand this question better, let’s look at object stores in more detail, and contrast with filesystems. Three salient features of a cloud object store (like AWS S3 or Backblaze B2, for example) and the objects stored within are as follows:
- The object store is an infinitely big ‘bucket’ for your data – software can use the S3 HTTP API to store as many objects as required. Such software needs to track each object stored. The object store does not slow down as it gets larger, since there is no overarching index growing and becoming unwieldy as objects are added (as is the case with a filesystem).
- Each object within the object store consists of:
- A unique ID or key – since object stores do not organise themselves via the familiar hierarchical folder structure used by filesystems, every object must have an identifier that is unique. The structure of the object store is flat – everything exists at the same level within the bucket. The ID typically includes the (globally unique) bucket name and taken together with an HTTP endpoint, can form a URL to access the object via the S3 API.
e.g. https://my-bucket-0e2f.amazonaws.com/my_holiday.jpeg - Data – the all important part where the actual file contents is stored, can be very large.
- Metadata – in addition to typical filesystem metadata like modification-date and file-size, custom fields can be stored against objects, without limitations. Some metadata might describe how the object is stored by the provider, e.g. fast/slow storage, how many times it is replicated, versioning, lifecycle rules etc. Unlike a filesystem, where a central index of metadata is managed (and becomes slow as number of files grows), each object describes itself via its metadata fields.
- A unique ID or key – since object stores do not organise themselves via the familiar hierarchical folder structure used by filesystems, every object must have an identifier that is unique. The structure of the object store is flat – everything exists at the same level within the bucket. The ID typically includes the (globally unique) bucket name and taken together with an HTTP endpoint, can form a URL to access the object via the S3 API.
- Object stores have a flat structure – Unlike filesystems, individual objects are stored in a flat address space, objects are organised according to their meta-data, not a hierarchical structure (like a filesystem). The illusion that the object store is a filesystem is presented by using the slash ‘/’ character as a separator within the object ID, allowing filesystem-like presentation in some interfaces. Many operations supported by filesystems, like reporting on total space used and navigating the hierarchy via child/parent pointers, are not possible.
While both object stores and filesystems allow file storage, an object store is a much more general purpose storage solution, very specifically designed for scalability, cloud hosting and web/API access.
Why P5 Archive and P5 Backup don’t write individual files to object stores
These products do more than simply copying files to alternative storage. They track the state of a customer’s source filesystem by maintaining an index (database) that can represent changes to the source data over time. These indexes also provide a vital reference point to compare against a filesystem to determine what has changed and needs to be saved again. Comparing an on-premise filesystem, file by file, objects in a cloud object store, would be extremely slow, at scale.
These point-in-time snapshots from filesystems, and can be retained indefinitely (in the case of archiving) or expire after a period of time (in the case of backup) according to users preferences. The index contains pointers to blocks (tape) or object data, stored either on LTO tape, disk or cloud object stores.
The design of these products, originally storing data on tape, is ideally suited to using object stores, since they already track filesystem information and metadata in their own indexes, and don’t need to read stored data (on tape or cloud) to make comparisons and calculate changes.
To perform these backup and archive tasks against a cloud object store, while writing individual files/folders to the object store would be impossible.
Cloud Object Stores and Latency
Writing backup and archive data to cloud object stores requires transmission of data over the customers internet/WAN connection to the cloud provider. P5 is therefore optimized in various ways to provide fast and efficient upload and download of data.
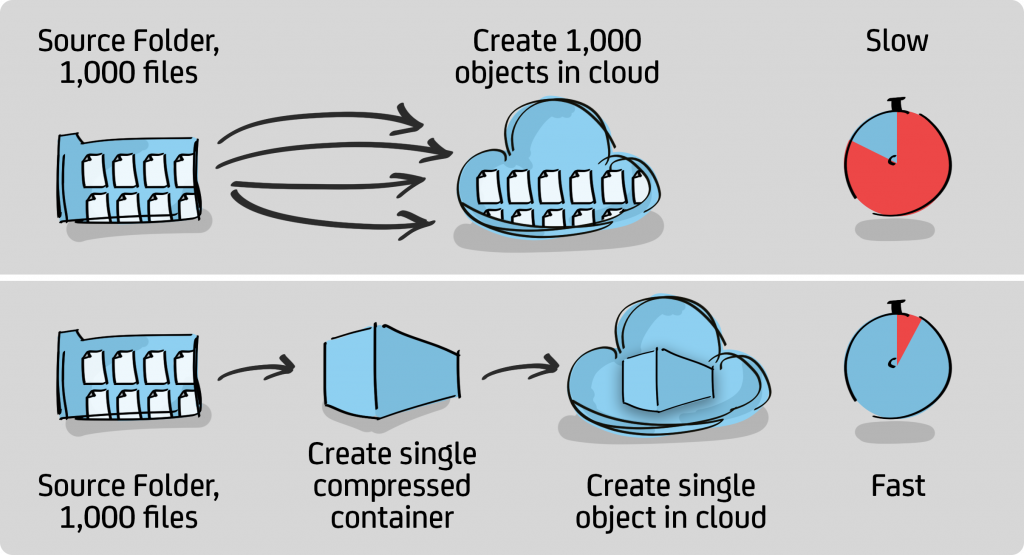
P5 introduces a new technology named ‘Container Volumes’ in version 7. Container volumes first combine multiple small files from the source filesystem together into single ‘container objects’ for upload to the object store. Larger files (e.g. > 256MB) may exist in their own container objects. Each container is compressed prior to upload. This avoids the case where many thousands of small files will result in an equal number of individual API operations against the cloud service, which would potentially be very slow.
Multi-part upload, when supported by the cloud provider, allows upload of a single object as a set of parts, each a portion of the object’s total data. P5 uploads these object parts independently, if transmission of any part fails, if is retransmitted without affecting other parts.
In addition to the above optimisations, P5 can assemble and upload multiple containers simultaneously to the object store. The customers total bandwidth to the cloud provider can be better utilised by having multiple, overlapping API calls occurring at the same time.
P5 Synchronize and Object Storage
Were P5 Synchronize to allow simply copying files from a filesystem to an object store (for example AWS S3), we would have the following issues.
We would have to rely on a 3rd party tool to present our S3 bucket in a filesystem-like way so that users might understand it. Which tool should we use?
We would have performance issues comparing local filenames and other metadata with remote cloud objects, to determine when something has changed and needed re-copying.
It would be slow, suffering from network latency when copying many small files.
Conclusion
While the object stores offered by cloud vendors appear to be just the same as familiar filesystems, this is something of an illusion. Object stores fulfil specific requirements around scalability, redundancy, security and web API access, making them very different from filesystems. Software designed to provide data-management workflows using cloud object stores as a target, needs to be tailored to work with the storage in an efficient manner. Archiware’s P5 Archive and P5 Backup products provide excellent operation against cloud storage.